写在前面
在Tensorflow搭建神经网络基础篇中,我们已经介绍了基本的神经网络的组成结构和搭建方法。在本博文中我们将会在上篇博文基础之上展示一些进阶内容。本博文主要涉及以下内容:Tensorboard可视化、分类学习任务、过拟合问题的产生以及解决方法。
1、可视化:Tensorboard
(1)什么是Tensorboard
TensorBoard可以将TensorFlow程序的执行步骤都显示出来,非常直观。并且,我们可以对训练的参数(比如loss值)进行统计,用图的方式来查看变化的趋势。
(2)示例程序
导入Tensorflow模块、Numpy模块。
1 | import tensorflow as tf |
定义添加层函数。tf.name_scope()函数在这里建立了一个变量空间,变量空间下包含几个变量权重(Weights)、偏差(biases)、预测值(Wx_plus_b)、
1 | def add_layer(inputs, in_size, out_size, n_layer, activation_function=None): |
定义输入数据和输出值函数。
1 | x_data = np.linspace(-1, 1, 300)[:, np.newaxis] |
在这里要注意x_data的输出值是经过变形得到的,主要是由于[:, np.newaxis]函数的原因,下面的例子将展示该函数的使用。
1 | import tensorflow as tf |
程序输出结果:

将占位符xs和ys设置在一个图层中,并将图层命名为inputs。xs在图层中显示为x_input,ys在图层中显示为y_input。
1 | with tf.name_scope('inputs'): |
设置隐藏层。
1 | with tf.name_scope('layer1'): |
设置输出层。
1 | with tf.name_scope('layer2'): |
设置损失函数。
1 | with tf.name_scope('loss'): |
设置训练优化函数。
1 | with tf.name_scope('train'): |
开始运行训练会话。
1 | sess = tf.Session() |
程序运行完毕后,在根目录下的log文件夹中包含一个envents文件。本次Tensorboard程序存储在Tensorboard文件夹中,文件结构如下:
1 | Tensorboard |
打开命令行窗口,激活tensorflow环境,执行tensorboard —logdir=”Tensorboard”语句,命令行将会出现一个链接,复制链接到Google Chrome浏览器,即可查看预训练有关的曲线、神经网络的流程图以及变量的统计图。
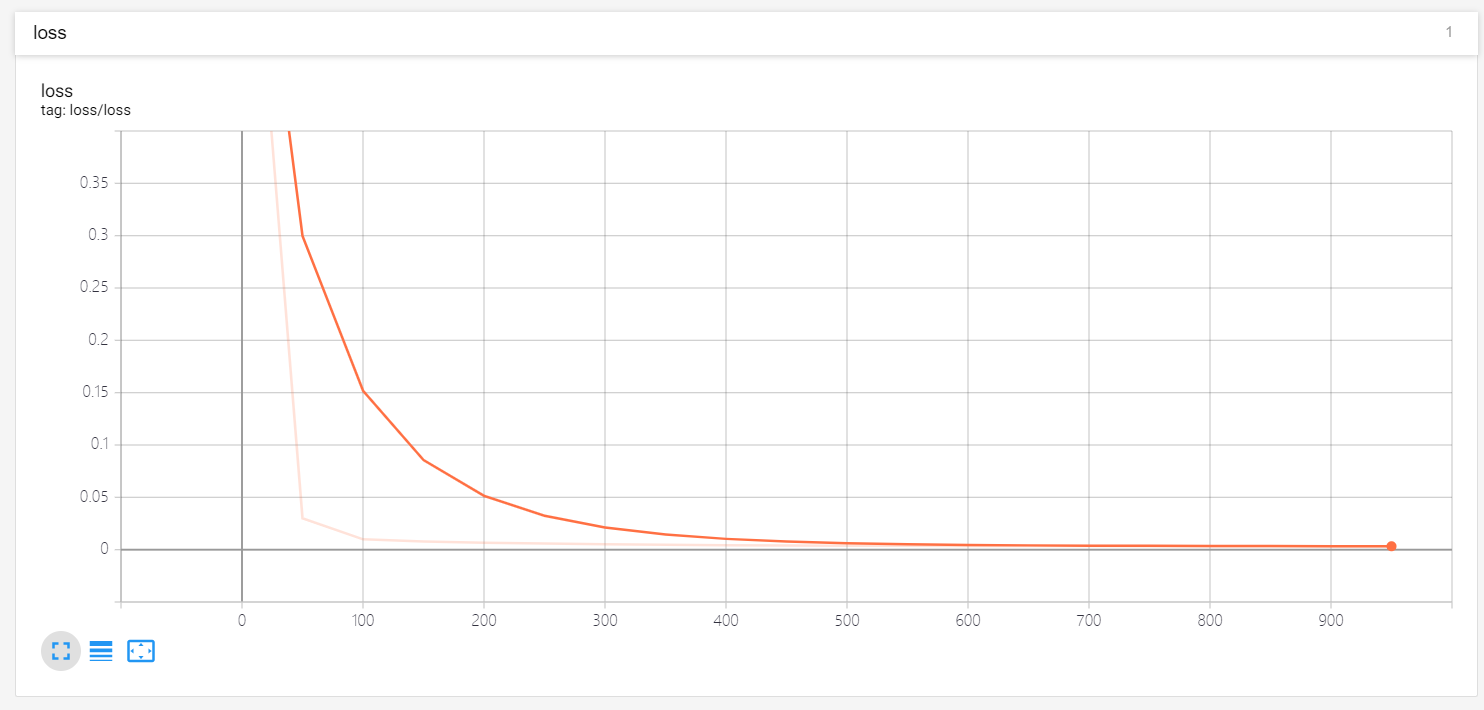
训练损失函数曲线:
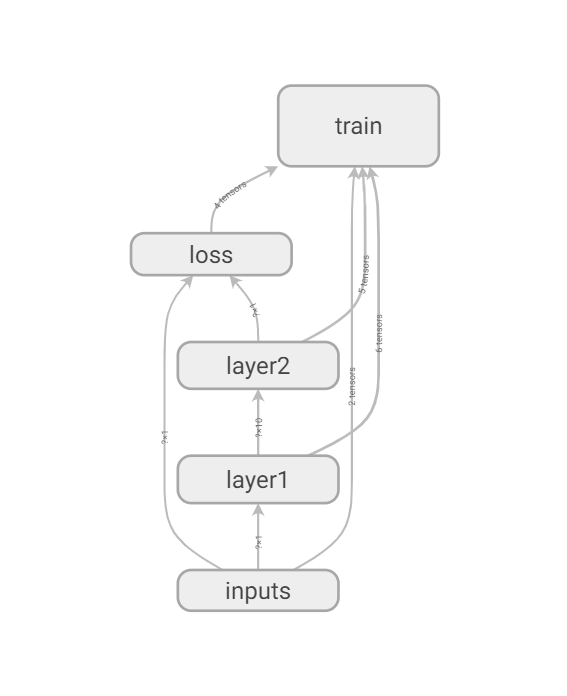
神经网络流程图:
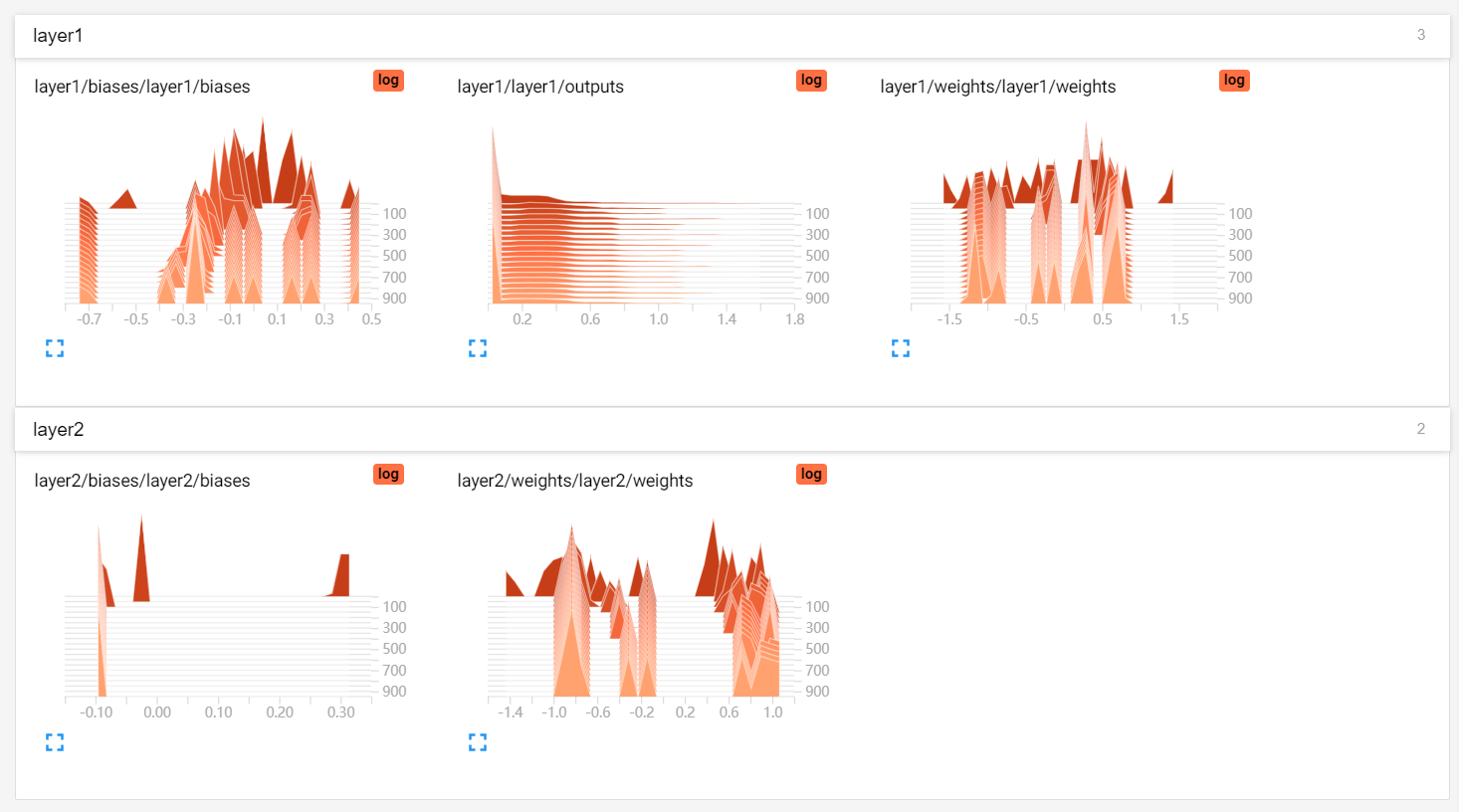
单层数据统计图:
2、分类学习任务:Classification
(1)什么是分类?
首先,需要思考以下什么是分类?很显然,分类是将数据集中的数据进行归纳整理的一个过程。现实中我们经常会遇到分类问题,例如何对书籍进行归纳和整理、计算机文件夹中的文件如何放置以及桌面物品的收纳整理等。在我们去分类的过程中,是否意识到一个问题,我们是依据什么标准去对杂乱的书籍、文件以及物品进行分类整理的呢?
答案其实隐藏在我们思考的过程中,只不过是我们没有意识到而已。当我们对这些东西进行分类整理的过程中,在脑海里都会有一个思考过程,就是这个东西和什么有关,要把它整理到哪个类别中呢,这个过程就是我们对文件和物品进行了一个打上标签印象的过程。在分类学习任务中,我们也需要对待分类的数据进行打标签的操作,之后通过神经网络进行分类操作。
神经网络分类的结果并不一定总是很优秀的,自然而然需要对分类结果进行评价。不同的要求对分类结果的评价也不尽相同。
(2)例程:MNIST手写体分类
数据集:MNIST手写体数据集,包括0-9十个数字的手写体。
MNIST数据集详细介绍:
| 文件名称 | 大小 | 内容 |
|---|---|---|
| train-images-idx3-ubyte.gz | 9,681 kb | 55000张训练集,5000张验证集 |
| train-labels-idx1-ubyte.gz | 29 kb | 训练集图片对应的标签 |
| t10k-images-idx3-ubyte.gz | 1,611 kb | 10000张测试集 |
| t10k-labels-idx1-ubyte.gz | 5 kb | 测试集图片对应的标签 |
导入Tensorflow模块。
1 | import tensorflow as tf |
读取MNIST数据集,数据集包含55000张训练集,每张图片的分辨率大小是28*28。
1 | from tensorflow.examples.tutorials.mnist import input_data |
定义添加层函数,添加层函数的定义参考上一篇博文“Tensorflow搭建神经网络基础篇”。
1 | def add_layer(inputs, in_size, out_size, activation_function=None): |
定义训练准确率函数。tf.argmax()函数是索引,tf.equal()是比较。tf.cast()将数据进行转换,由于tf.equal()返回的向量或矩阵的组成元素是True或者False,因此采用tf.cast()将True转换为1,False转换成0。tf.reduce_mean()求解均值。
1 | def compute_accuracy(v_xs, v_ys): |
注:下面一段程序可以更加清晰的认识tf.cast()函数和tf.reduce_mean()函数。
1 | import tensorflow as tf |
定义输入和输出占位符。由于每张图片的分辨率大小是28*28,因此需要输入784个像素数据;输出类别为10,对应MNIST数据集的数据组成类别。
1 | xs = tf.placeholder(tf.float32, [None, 784]) |
定义输出层。在这里并没有定义隐藏层,而是直接定义了一个输出层。通常神经层由输入层、隐藏层和输出层组成,在这里省略了隐藏层,这样构成的神经网络实际上是一个由输入层和输出层构成的二层的网络,数据的输入直接作为输入层。
1 | prediction = add_layer(xs, 784, 10, activation_function=tf.nn.softmax)#激励函数采用了softmax函数 |
定义损失函数,在这里采用了交叉熵作为损失函数。
1 | cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys*tf.log(prediction), reduction_indices=[1])) |
定义神经网络的训练优化器。TensorFlow优化器GradientDescentOptimizer是一个实现梯度下降算法的优化器。在这里取值是0.5表示以0.5的效率来最小化误差交叉熵(cross_entropy)。
1 | train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy) |
初始化变量。
1 | init = tf.global_variables_initializer() |
初始化会话控制Session。
1 | sess = tf.Session() |
初始化变量。
1 | sess.run(init) |
开始训练神经网络。执行1000次训练,在这里采用了批量梯度下降算法,因此设置每一次一批批训练数据为100个。注意,batch_xs是训练值,其输出是prediction;batch_ys是真实值(也就是设置的标签),其主要作用是计算交叉熵(cross_entropy)。在这里每50次输出一次神经网络的准确率值。
1 | for i in range(1000): |
神经网络训练准确率输出结果:

可以看到随着训练次数的不断增加,这个两层的简单神经网络已经能够实现很不错的分类效果。当然,我们可以调整训练次数和batch_size来实现更加准确的训练,然而训练并不是无止境的。盲目的扩大训练参数很可能会使神经网络陷入过拟合,也就是过度学习的问题。接下来我们会针对过拟合问题进行概念上的介绍,并且介绍如何防止过拟合的解决方法。
3、过拟合:Overfitting
为了使训练数据与训练标签一致,而对模型过度训练,从而使得模型出现过拟合(over-fitting)现象。具体表现为,训练后的模型在训练集中正确率很高,但是在测试集中的变现与训练集相差悬殊,也可以叫做模型的泛化能力差。下图展示了分类模型中过拟合的现象。
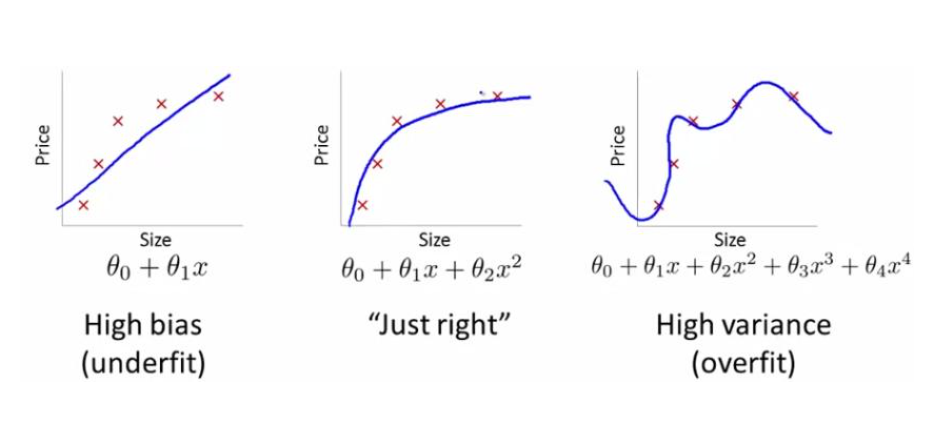
也就是说神经网络只对训练集有很好的效果而对测试集效果很差,模型的泛化能力弱这样的现象被称为过拟合现象。
4、过拟合的解决方法:Dropout
Dropout是解决神经网络出现过拟合情况的一种常用的方法。Dropout方法是在一定的概率上(通常设置为0.5,原因是此时随机生成的网络结构最多)隐式的去除网络中的神经元,如下图:
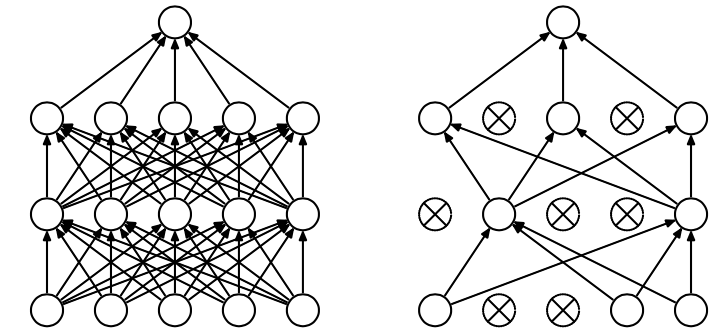
Tensorflow提供了Dropout方法来解决过拟合问题,在Tensorflow中可以很方便地使用。
示例程序:
导入Tensorflow模块以及从sklearn数据库导入数据。
1 | import tensorflow as tf |
定义添加层函数。
1 | def add_layer(inputs, in_size, out_size, n_layer, activation_function=None):#在此激励函数(activation function)是None,代表线性关系 |
准备数据。数据最后被分为训练集和测试集。train_test_split()函数是用来随机划分样本数据为训练集和测试集,参数介绍如下。
train_X,test_X,train_y,test_y = train_test_split(train_data,train_target,test_size=0.3,random_state=5):
train_data:待划分样本数据;
train_target:待划分样本数据的结果(标签);
test_size:测试数据占样本数据的比例,若整数则样本数量;random_state:设置随机数种子,保证每次都是同一个随机数。若为0或不填,则每次得到数据都不一样。
1 | digits = load_digits()#从sklearn.datasets导入的数据 |
定义占位符。
1 | keep_prob = tf.placeholder(tf.float32) |
定义隐藏层和输出层。注意输入数据的个数和维度是两个不同的定义。
1 | #add output layer |
定义损失函数,在这里采用交叉熵进行计算,并且采用tf.summary.scalar()函数在Tensorboard中进行显示。
1 | cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys*tf.log(prediction), reduction_indices=[1]))#交叉熵,loss |
定义神经网络的训练优化器。TensorFlow优化器GradientDescentOptimizer是一个实现梯度下降算法的优化器。在这里取值是0.5表示以0.5的效率来最小化误差交叉熵(cross_entropy)。
1 | train_step = tf.train.GradientDescentOptimizer(0.6).minimize(cross_entropy) |
开启会话窗口。
1 | sess = tf.Session() |
执行训练程序。在这里keep_prob指保留结果的概率,一般在大量数据训练时,为了防止过拟合,添加Dropout层,设置一个0~1之间的小数。在这段程序中,训练次数设置为500次。
1 | sess.run(tf.initialize_all_variables()) |